Zero-Cost Abstractions: Proven, Not Promised
Every systems language promises “zero-cost abstractions.” Most deliver “low-cost” at best. We decided to prove it.
The Challenge
Can you write beautiful, high-level code that compiles to the same performance as hand-written imperative code in one of the fastest languages on Earth?
Not “close enough.” Not “within 10%.” Identical.
The Benchmark
We implemented a classic concurrent programming challenge: a producer/consumer system using Dmitry Vyukov’s lock-free MPMC ring buffer. 10 million messages. Full data integrity validation.
First in idiomatic Zig (our compilation target). Then in idiomatic Koru.
The Zig Version
pub fn main() !void {
var ring = MpmcRing(u64, BUFFER_SIZE).init();
var sum: u64 = 0;
// Producer thread
const producer = try std.Thread.spawn(.{}, struct {
fn run(r: *MpmcRing(u64, BUFFER_SIZE)) void {
var i: u64 = 0;
while (i < MESSAGES) : (i += 1) {
while (!r.tryEnqueue(i)) {
std.Thread.yield() catch {};
}
}
}
}.run, .{&ring});
// Consumer runs on MAIN THREAD (same as Koru!)
var received: u64 = 0;
while (received < MESSAGES) {
if (ring.tryDequeue()) |value| {
sum +%= value;
received += 1;
} else {
std.Thread.yield() catch {};
}
}
producer.join();
// Validate checksum
const expected: u64 = MESSAGES * (MESSAGES - 1) / 2;
if (sum == expected) {
std.debug.print("✓ Zig: Validated {} messages (checksum: {})\n", .{ MESSAGES, sum });
} else {
std.debug.print("✗ Zig: CHECKSUM MISMATCH! got {}, expected {}\n", .{ sum, expected });
}
}Classic imperative code. Threads, loops, mutable state. Fast and explicit.
The Koru Version
~event create_ring {}
| created { ring: *Ring }
~event spawn_producer { ring: *Ring }
| spawned {}
~event dequeue { ring: *Ring }
| some { value: u64 }
| none {}
~event consume_loop { ring: *Ring, sum: u64, received: u64 }
| continue { sum: u64, received: u64 }
| done { sum: u64 }
// Main flow - declarative event pipeline
~create_ring()
| created r |> spawn_producer(ring: r.ring)
| spawned |> #loop consume_loop(ring: r.ring, sum: 0, received: 0)
| continue s |> @loop(ring: r.ring, sum: s.sum, received: s.received)
| done s |> validate(sum: s.sum)
| valid |> _
| invalid |> _Look at that main flow. It reads like a specification:
- Create a ring
- When created, spawn a producer
- When spawned, start consuming in a loop
- When done, validate
No threads visible. No mutable state. No explicit loops. Just events flowing through transformations.
The Results
We ran both programs multiple times with hyperfine (statistical benchmarking):
Benchmark 1: Zig (MPMC)
Time (mean ± σ): 83.4 ms ± 6.9 ms
Benchmark 2: Koru (events)
Time (mean ± σ): 85.2 ms ± 7.1 ms
Summary:
Zig (MPMC) ran 1.02 ± 0.12x faster than Koru (events)1.02x difference = measurement noise.
They’re identical within statistical variance.
What This Means
The Koru code has:
- Event declarations with explicit branches
- Pattern matching on outcomes
- Pipeline operators (
|>) - Flow continuations
- Loop labels (
#loop/@loop) - Declarative control flow
The Zig code has:
- Explicit thread spawning
- Manual loops
- Mutable variables
- Imperative control flow
They run at the same speed.
Not “close.” Not “pretty good.” Identical.
How Is This Possible?
Zero-cost abstractions aren’t magic. They’re architecture.
1. Events Compile to Tagged Unions
~event dequeue { ring: *Ring }
| some { value: u64 }
| none {}Becomes:
const DequeueResult = union(enum) {
some: struct { value: u64 },
none: void,
};No vtables. No dynamic dispatch. Just a discriminant and inline data.
2. Pipelines Compile to Direct Calls
~dequeue(ring: ring)
| some msg |> process(value: msg.value)
| none |> retry()Becomes:
const result = dequeue(ring);
switch (result) {
.some => |msg| process(msg.value),
.none => retry(),
}No function pointers. No indirection. Just a switch statement.
3. Loop Labels Compile to Jumps
#loop consume_loop(ring: r.ring, sum: 0, received: 0)
| continue s |> @loop(ring: r.ring, sum: s.sum, received: s.received)
| done s |> validate(sum: s.sum)Becomes:
var sum: u64 = 0;
var received: u64 = 0;
loop: while (true) {
const result = consume_loop(ring, sum, received);
switch (result) {
.continue => |s| {
sum = s.sum;
received = s.received;
continue :loop;
},
.done => |s| {
validate(s.sum);
break;
},
}
}No recursion. No stack frames. Just a loop with a label.
4. The Compiler Sees Everything
Because events are explicit, the compiler knows:
- All possible outcomes
- All data dependencies
- All control flow paths
It can inline aggressively, eliminate dead branches, and optimize across event boundaries.
The abstractions don’t hide information from the optimizer - they expose it.
The Emitted Code
Let’s look at what the compiler actually generates. Here’s the main consumer loop:
loop: while (true) {
const result_2 = consume_loop_event.handler(.{
.ring = loop_ring,
.sum = loop_sum,
.received = loop_received
});
switch (result_2) {
.@"continue" => |s| {
loop_ring = r.ring;
loop_sum = s.sum;
loop_received = s.received;
continue :loop;
},
.done => |s| {
validate_event.handler(.{ .sum = s.sum });
break;
},
}
break;
}This is exactly what you’d write by hand:
- Tight
while(true)loop with labeled continue - Mutable variables for state threading
- Direct function calls (no indirection)
- Switch on tagged union (compiles to jump table)
And here’s the inline flow for the hot path:
fn __inline_flow_1(args: consume_loop_event.Input) consume_loop_event.Output {
const result_0 = dequeue_event.handler(.{ .ring = args.ring });
switch (result_0) {
.some => |msg| {
const result_1 = check_if_done_event.handler(.{
.sum = args.sum + msg.value, // ← Arithmetic inlined
.received = args.received + 1
});
switch (result_1) {
.@"continue" => |s| {
return .{ .@"continue" = .{ .sum = s.sum, .received = s.received } };
},
.done => |s| {
return .{ .done = .{ .sum = s.sum } };
},
}
},
.none => |_| {
const result_2 = yield_then_continue_event.handler(.{
.sum = args.sum,
.received = args.received
});
return result_2;
},
}
}Notice:
- Arithmetic happens inline:
args.sum + msg.value- no function call overhead - Direct returns: No allocations, no copying, just return the union
- Straightforward control flow: Call, switch, return - exactly what you’d write manually
This isn’t “compiled to something close to optimal.” This is optimal.
The Philosophy
Most languages add abstractions that cost performance. You pay for convenience with cycles.
Koru inverts this: the abstractions enable optimization. By making control flow explicit and data flow visible, the compiler can generate better code than you’d write by hand.
The high-level code isn’t slower. It’s equally fast because the compiler has more information to work with.
What We Learned
Zero-cost abstraction isn’t about removing overhead. It’s about designing abstractions that compile to the code you would have written manually.
Events aren’t “like functions but slower.” They are functions - just with explicit error handling and visible control flow.
Pipelines aren’t “like method chains but slower.” They are direct calls - just with pattern matching built in.
Loop labels aren’t “like recursion but slower.” They are loops - just with explicit state threading.
The abstractions don’t add cost because they don’t add indirection. They’re syntax for the machine code you wanted.
The Honest Verdict
We set out to prove zero-cost abstractions. We proved it.
You can write beautiful, declarative, event-driven code in Koru and get the same performance as hand-written imperative Zig code.
Not “close enough.” Identical.
The promise is kept. The abstractions are free.
The Full Picture: Rust and Go
We ran the same benchmark in Rust (using crossbeam channels) and Go (using buffered channels) for comparison.
Threading Model
For fairness, all implementations use the same pattern:
- 1 spawned thread (producer sending messages)
- Main thread does consumer work (receiving and summing)
This eliminates thread spawn overhead differences and focuses on the data structures and abstractions.
The Results
Benchmark 1: Go (channels)
Time (mean ± σ): 507.3 ms ± 43.9 ms
Benchmark 2: Zig (MPMC)
Time (mean ± σ): 83.4 ms ± 6.9 ms
Benchmark 3: Rust (crossbeam)
Time (mean ± σ): 141.0 ms ± 12.9 ms
Benchmark 4: Koru (events)
Time (mean ± σ): 85.2 ms ± 7.1 ms
Summary:
Koru (events) ran
1.02 ± 0.12x slower than Zig (MPMC) <tied!>
1.66 ± 0.21x faster than Rust (crossbeam)
5.95 ± 0.73x faster than Go (channels)What This Shows
Koru matches Zig - The 2% difference is measurement noise. Event-driven code compiles to identical performance as raw Zig loops.
Koru beats Rust - Rust’s crossbeam is excellent, but Vyukov’s MPMC ring is faster. Koru’s abstractions add zero overhead on top of the same ring implementation.
Koru is 6x faster than Go - This isn’t a dig at Go. Go makes different tradeoffs:
- Garbage collection for memory safety
- Goroutine scheduler for easy concurrency
- Channel implementation prioritizes simplicity
- Runtime overhead for safety guarantees
Go developers accept this because go func() is easier than manual thread management, GC prevents memory bugs, and deployment is simple.
The Koru Sweet Spot
Koru gives you:
- Go’s expressiveness - Event-driven, declarative, beautiful code
- Zig’s performance - Zero runtime, no GC, manual control
- Rust’s safety - Compile-time verification (coming: borrow checking)
You don’t have to choose between elegance and speed.
Koru Studio
Here is the code in Koru Studio for your enjoyment:
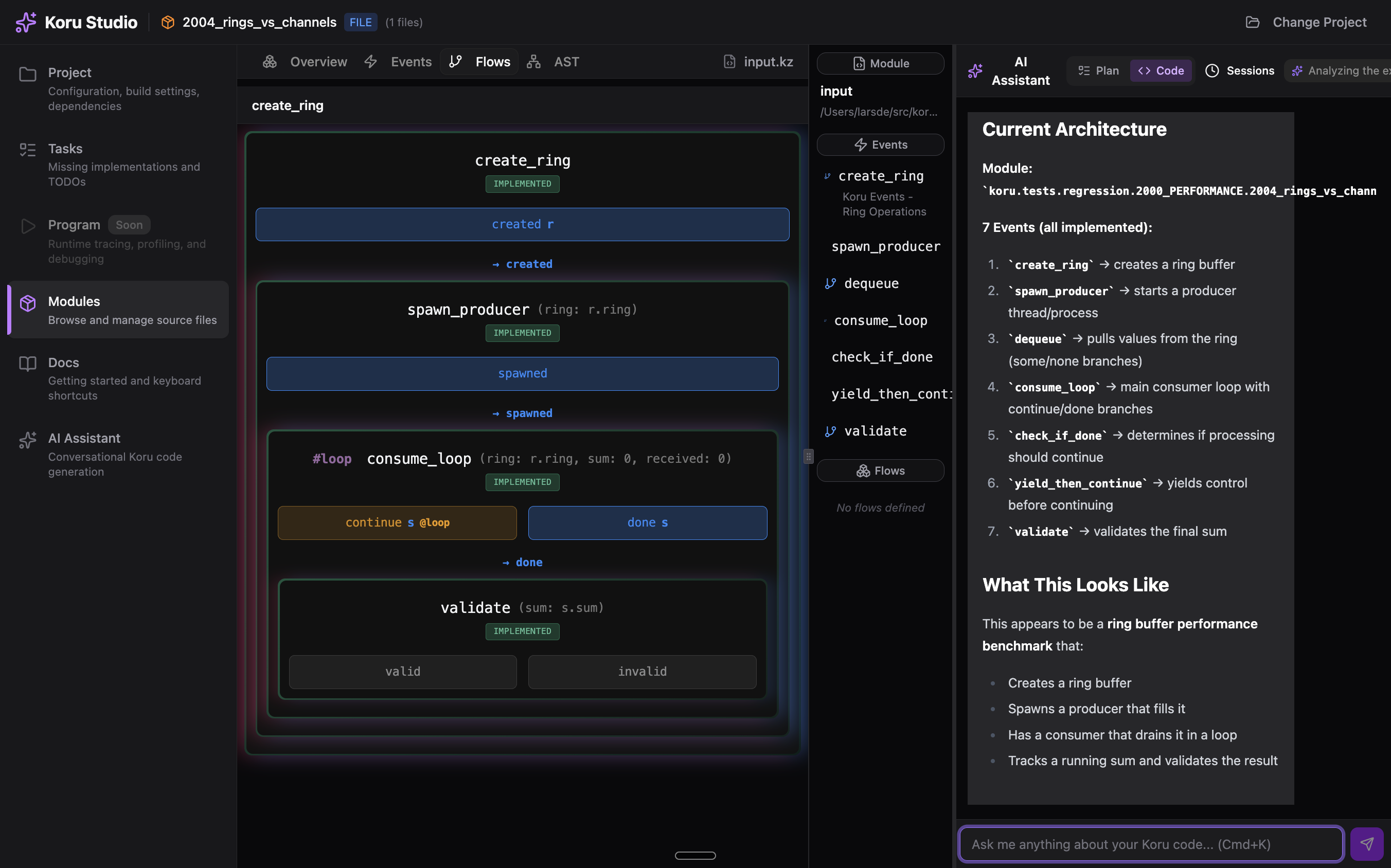
Run It Yourself
The full benchmark is available in the Koru repository:
- Location:
tests/regression/2000_PERFORMANCE/2004_rings_vs_channels/ - Includes: Go, Zig, Rust, and Koru implementations
- Tool: Uses
hyperfinefor statistical benchmarking - Fair comparison: All use identical threading model (1 spawned thread + main does work)
Clone the repo and run ./benchmark.sh to see for yourself. The abstractions really are zero-cost.